


{kind=link}
When neuroscientists gather in the Spanish city of Seville in May for the annual Dopamine Society meeting, one discussion could be unusually lively. Session 31 will feature a debate between researchers who fundamentally disagree about the role dopamine has in the brain.
Untangling the connection between dopamine and ADHD
Dopamine is one of the most extensively studied neurotransmitters, chemicals that convey signals from cell to cell. It’s the one with the highest profile outside neuroscience: often known as the ‘pleasure chemical’, it’s depicted as the hit of reward that people get from recreational drugs or scrolling through social media.
That’s a gross simplification of what dopamine does; on that, researchers agree. But beyond that, where once there was a simple model that explained how dopamine works in the brain, now there are challenges that seek to amend the theory — or even to overturn it.
This could have implications not only for basic neuroscience, but also for clinicians trying to explain and treat conditions such as attention deficit hyperactivity disorder (ADHD) and addiction. If the model is wrong or needs modification, then so might some of the assumptions about what drives these disorders and the best way to treat them.
The classic idea, known as the reward prediction error (RPE) hypothesis, is that bursts of dopamine in the brain link stimuli to rewards, helping to reinforce associations that fulfil a need for an animal or a person. The model has dominated and guided research in the field for decades, offering a mathematical framework to interpret data from animal experiments, and it does a good job of explaining behaviour.
This was a valuable rarity for researchers struggling to overlay simple theories onto the intense complexity of the brain. “Dopamine was the one field of neuroscience where we had a computational model that explained what the signal was and what it was computing,” says Mark Humphries, a neuroscientist at the University of Nottingham, UK. People in the field knew that some of the assumptions involved in the RPE model were simplistic. But as a working understanding of part of the brain, it was seen as a major step forwards.
In the past few years, that primacy has begun to slip. About a decade ago, experimental techniques emerged that made it easier to monitor the release of dopamine from neurons in animal experiments. This threw the field wide open, with more laboratories able to gather and analyse data. And many of the data from these studies suggested that dopamine has functions in the brain that go way beyond reward, suggesting roles in cognitive functions such as attention, working memory and even social behaviours. Other studies showed that dopamine neurons can respond to new stimuli, threats and movement. The original model is no longer sufficient to explain all of this, Humphries says.
That leaves the field wrestling with a question, one that those who attend Session 31 in Seville will address: is this the end of the road for neuroscience’s most cherished model? Or is the idea, and the way it has been adapted by clinicians trying to understand ADHD, schizophrenia and addiction, now too big to fail? “I do think that the framework is insufficient,” says Kauê Costa, a neuroscientist at the University of Alabama at Birmingham. “But you know, if you aim at the king, you better not miss.”
Predicting reward
The idea of reward prediction has its roots in the famous twentieth-century experiments of Russian psychologist Ivan Pavlov. He established the idea of classical conditioning, showing that dogs learnt to associate environmental cues with the expectation of food. The principle inspired computer scientists trying to develop theories of machine learning in the 1960s, and was used in the 1990s to design neural networks.

Dopamine neurons (green) growing with other mature neurons (red) in a dish. DNA in the nucleus of each cell is shown in blue.Credit: Jian Feng
In 1997, neuroscientists reclaimed the idea to explain data from a primate experiment1. Wolfram Schultz, now at the University of Cambridge, UK, and his colleagues showed how the activity of dopamine neurons deep in the brain shifted as a monkey learnt to expect a reward. At first, these neurons fired and released dopamine when the animal unexpectedly received a drop of fruit juice. Then the experimenters turned a light on before the juice arrived, and found that afterwards, the dopamine neurons were triggered by the light — the predictor of the reward — and not the juice. If the monkey expected but didn’t receive juice, there was a downward blip in the firing rate of dopamine neurons.
The RPE hypothesis says that dopamine signals allow the brain, over time, to make better estimates of where a reward — food, a mate, a safe place — might come from.
It’s a “shining highlight of computational neuroscience”, says Nathaniel Daw, a neuroscientist at Princeton University in New Jersey. The theory links bursts in the activity of individual neurons with complex actions. “It’s the story that goes all the way from spikes and synapses to behaviour and addiction, and in a pretty plausible way.”
Proponents of the theory say that, at its heart, dopamine surges are signalling ‘value’: they provide information about the subjective worth, desirability or usefulness of an object, action or outcome, and they help the animal to decide priorities. In the classic example, the first time a child hears an ice-cream-van jingle, they are surprised and delighted to then get an ice cream. The value of that unexpected reward generates a surge in activity among neurons that release dopamine. On repeated exposures, the value (and the dopamine surge) shifts to become entirely associated with the jingle; the reward appears as expected, so there is no error and therefore no signal. If, one day, the child hears the jingle and doesn’t get ice cream, this generates a negative RPE — a depression of activity — to weaken the association (see ‘The classic theory of reward’). With time, the association strengthens the connections between some neurons and so reshapes neural pathways.

Over the decades, researchers have taken the RPE theory and broadened it, using it to explore the way in which the brain learns and stores predictions about lots of things besides reward. This bigger idea is called temporal difference reinforcement learning (TDRL). It uses the discrepancy between predicted and actual values over time to update predictions and optimize actions to maximize future gain. Plenty of experiments have produced data that supports the TDRL idea. But in the past few years, there has also been a rise in high-profile papers that expand this simple picture.
Some studies have examined subgroups of dopamine neurons and found that many of them encode a non-reward variable in addition to signalling about reward. For example, some of these neurons also respond to the animal’s position in a maze, or its speed2. Others seem to be encoding the extent to which an animal’s current movement is bringing it closer to or farther from its goal, as opposed to the value of the goal itself3.
Other work has added more strings to dopamine’s bow. Dopamine signals can encode several potential rewards at once and help animals to prioritize some over others4. Dopamine responses can be tuned towards water when a songbird is thirsty, for example, but retune to prioritize singing when a potential mate is nearby — although how these neurons change their tuning is unclear.
How human brains got so big: our cells learned to handle the stress that comes with size
The classic theory of dopamine is that it signals errors in reward prediction, but recent findings are challenging that idea. A 2025 study suggested that dopamine is involved in predicting actions, too, which has the effect of encouraging repeated actions5. This implies that repetitive behaviours or addictive habits might not be a consequence of RPE. Similarly, dopamine has been observed to signal predictions about threats6, aversive stimuli7 and the novelty of a stimulus8, rather than reward.
The question raised by such findings boils down to whether the field should stop modifying and adding to the existing model to explain fresh data, and instead “move to new classes of models with different fundamental underlying assumptions”, says Geoffrey Schoenbaum, a neuroscientist at the Johns Hopkins School of Medicine in Baltimore, Maryland, who will run the Seville session. “After a period of clear dominance, the RPE hypothesis is showing its age,” he says.
Toppling the king
One neuroscientist who is keen to unseat dopamine’s link to reward is Erin Calipari, a pharmacologist at Vanderbilt University in Nashville, Tennessee. Dopamine, she thinks, is better viewed through a broader lens as a way for the brain to steer and encourage information-processing and learning. But she has found it difficult to publish papers that make that case.
In 2021, Calipari was a new principal investigator developing her own lab and readying one of its first papers. It showed that dopamine release in mice was a response to stressful stimuli, such as mild electric shocks to their feet7. The result can’t be explained by reward, and it faced significant headwinds from reviewers — and requests for further experiments, some designed to produce data linked to reward. “People were really mad about it,” she says. “It was like the rebuttal from hell.”
One of the most direct challenges to the RPE crown comes from Vijay Mohan Namboodiri, a neuroscientist at the University of California, San Francisco, who has suggested an alternative model that is basically the reverse of RPE. Whereas RPE holds that an animal sees a cue and later associates it with a reward, Namboodiri argues it’s the other way around: an animal that experiences a reward looks backwards in time to identify the cue.
His team did various tests with mice to try to differentiate between this retrospective learning and the original RPE theory9. For instance, the researchers gave untrained mice sugar-water rewards at random intervals. The RPE theory predicts that their dopamine response should be high initially and then drop as they learn that rewards do sometimes appear. But, Namboodiri reasoned, if an animal is looking back in time to find a cue, then dopamine should increase with repeated experience of rewards, because it is signalling that these events are meaningful and initiating a memory search to learn what caused them. The test results backed up his theory, which he calls adjusted net contingency for causal relations (ANCCR).
Namboodiri argues that this picture of retrospective learning makes more intuitive sense. More often, people learn by getting a reward and then looking back for a cause, than by tracking every single bit of their environment and how it corresponds to a reward received only later on.
His idea has had a mixed response. “I haven’t spoken to anyone who understands that model. We did a whole journal club on it,” says Humphries.
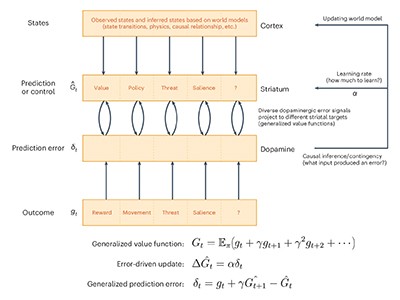
Explaining dopamine through prediction errors and beyond